
📖 What is Contextual Vector?
A Contextual Vector is essentially a heading or vocabulary list that represents the macro-context of a domain. It helps search engines like Google differentiate between different contextual domains by analyzing word occurrences.
🔍 How It Works:
- ✅ Each domain has a unique set of terms that frequently occur.
- ✅ Google’s User-Context-Based Search Engine Patent uses this to identify and classify content relevance.
📌 Example:
- 🏀 Sports Domain → "Game," "Player," "Score"
- 🍳 Cooking Domain → "Recipe," "Ingredients," "Cook"
By understanding Contextual Vectors, websites can align their content with domain-specific terminology, improving semantic relevance and search rankings! 🚀
📖 Example:
Think of a Contextual Vector as a word cloud for a book. It represents the most frequently used words, helping identify the book’s main topic.
📌 Example 1: Gardening Book 🌱
- 📚 Frequent Words: Plants, Flowers, Soil, Watering
- ✅ Contextual Vector → Suggests the book is about Gardening
📌 Example 2: Cooking Book 🍳
- 📚 Frequent Words: Recipe, Baking, Ingredients, Oven
- ✅ Contextual Vector → Suggests the book is about Cooking
🔎 How Google Uses Contextual Vectors:
Search engines analyze the most commonly used words in a web domain to determine its topic. This helps Google differentiate between a gardening website and a cooking website, ensuring better search results and semantic relevance. 🚀
Koray Notes:
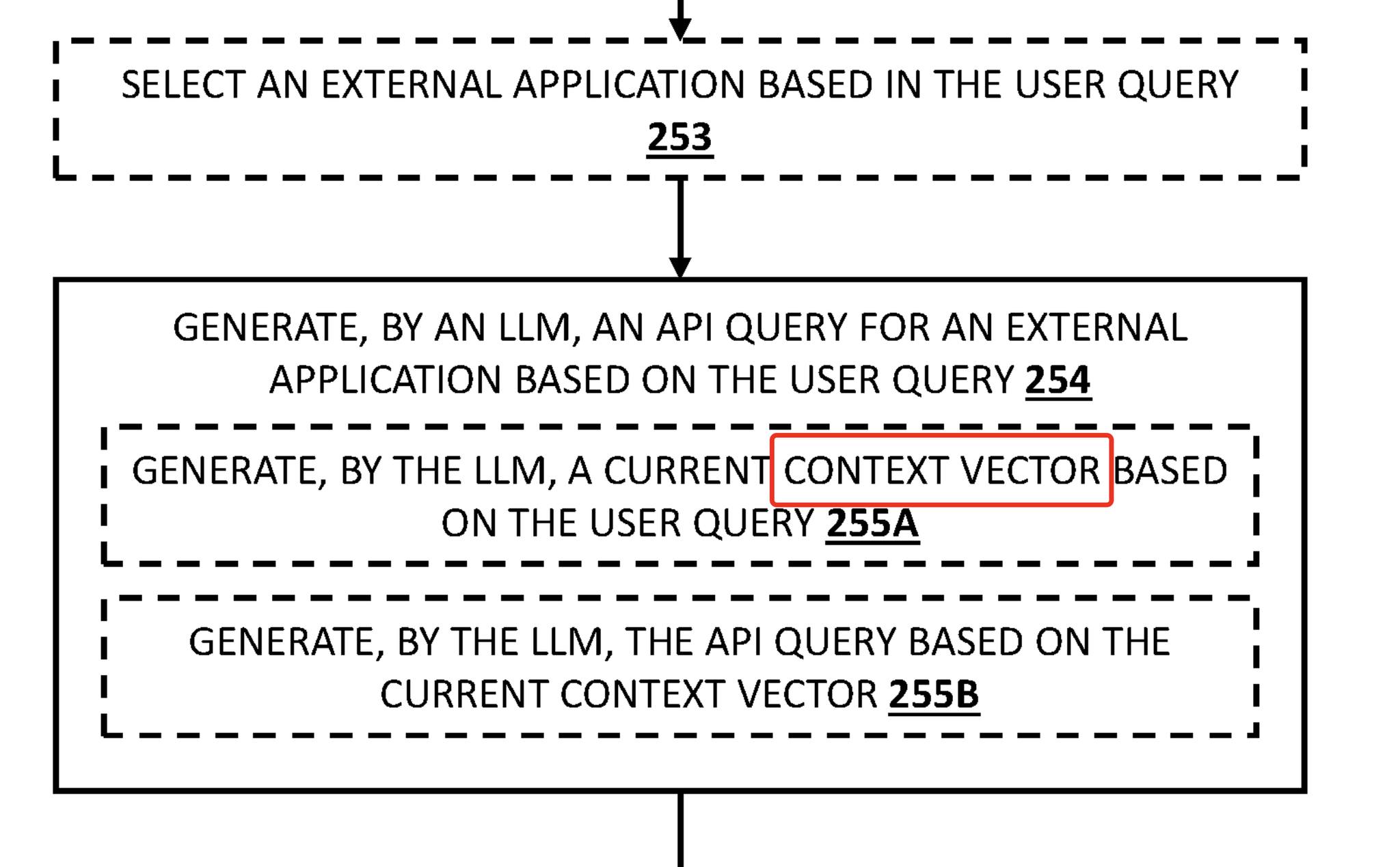
🚨 There’s a strong resemblance between Google’s Passage Scoring-related patents (as described by Steven D. Baker) and recent LLM-related patents.
Years ago, we integrated concepts like “context vectors” into our framework through Inquisitive Semantics and Query Semantics—long before the current hype.
When you search using Google AI Mode, the system performs query augmentation with a contextual direction. For example, when asking about symptoms, it can shift toward:
- Common symptoms
- Nasal / head / skin / eye symptoms
- Rare symptoms
These “directions” represent distinct contextual vectors, drawn from the query’s vocabulary and semantics.
What follows is:
- Question generation
- Passage ranking
- Passage generation
This is exactly where Semantic SEO comes in—working with the mathematical possibilities of context, vocabulary, and information quality.
If your website has more rank-worthy documents and quality passages, you’ll appear more often in LLMs and Google AI Mode.
But that doesn’t mean you should repeat the same info endlessly. That’s how you trigger what Google internally calls a “gibberish score” (confirmed in the API leak).
🔍 The key is to connect the main attribute to the context of the query, and then represent related attributes through that central lens.
“A distance in embedding space (e.g., L1/L2, cosine similarity, or correlation) is computed between a context vector and precomputed document embeddings…”
This is about relevance, not factual accuracy. (Factuality is a topic for another post.)